2 EXMARALDA workflow
2.1 general
- info/download: EXMARALDA Partitur Editor
- assuming you have successfully installed exmaralda on your system here follow some instructions on how to work with it.
- you cannot open the .exb (exmaralda format) directly from the HU box, you have to download and open the files in the partitureditor.
2.2 transcription: from scratch in template
note: this method is demanding fewer technical skills, but takes longer to transcribe = type the text. if you decide to do use a more technical demanding method, which allows for easy and fast transkription, skip to section 3.3.
2.2.1 preliminary
- open the original .pdf you want to transcribe and the partitur editor. best is to have a parallel view of the .pdf and the partitur in horizontal split
- open the template <LLDM_exmaralda_basictemplate.exb> which you download from the HU box or here.
- in this template you have already the necessary tiers for the transkription and annotation created. (without content)
2.2.2 speakertable
- edit the speakertable to relabel the tiers:
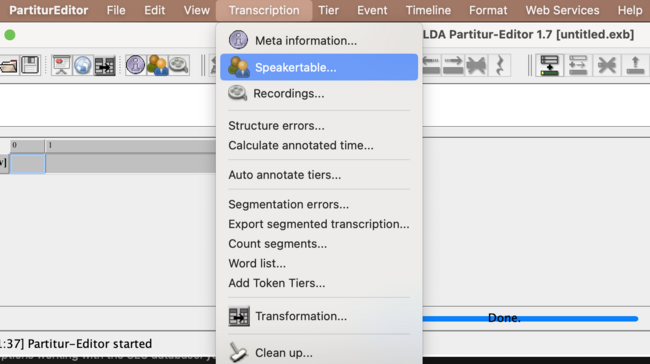
- here you insert the speaker abbreviation as label from the .pdf (e.g. MIM), the language used in the transcript and the L1/L2 if named in the questionaire.
- then fill in the values of the template attributes for the speaker with the corresponding values of the transcript (from the questionaire)
- left is the attribute name, right the value which is to adapt
2.2.3 metadata
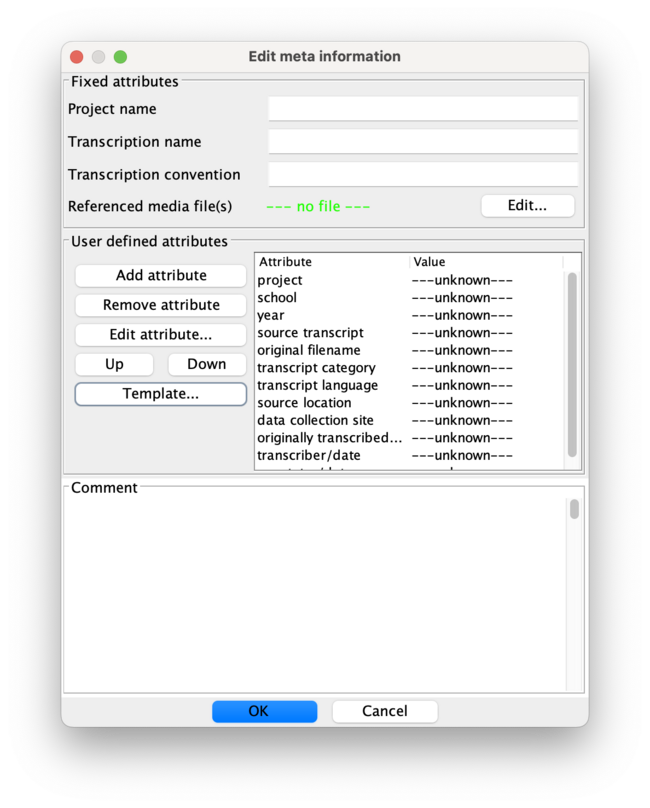
- edit the transcript metadata:
- like above fill in the values of the template attributes for the metadata with the corresponding values of the transcript (from the questionaire)
- left is the attribute name, right the value which is to adapt
2.2.4 transcribe the text from the .pdf:
- click into a segment
- type the text
- at the end of one unit (which is still to define: either sentence, word or syntactic unit) insert a <space:leerzeichen:whitespace> to signal the chat processor, that this is a segment. when you done with one segment and the end of available empty segments of the transcription tier is reached, one new segment is opened when you hit <return:enter> and you can type in the next unit.
- precisely: for text tokenised per word the steps will be:
- type word > type whitespace > hit return
- note: in each after these steps automatically opened new segment you have to type the first character twice, since the input is possible only when you started typing. you will see what is meant by trying…
- repeat for every word (AND punctuation mark!)
- type word > type whitespace > hit return

if you need to insert an empty segment in the middle of the transcript (because you forgot to transcribe a word e.g.) you can split an event which creates an empty segment.
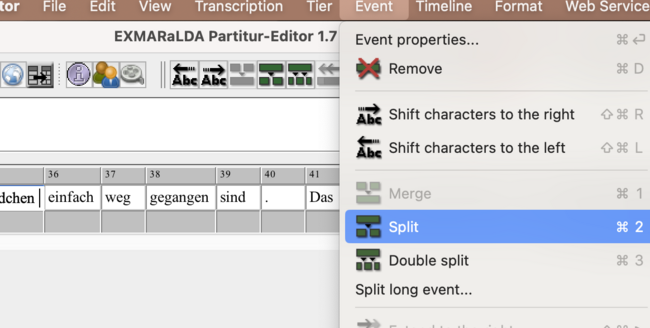
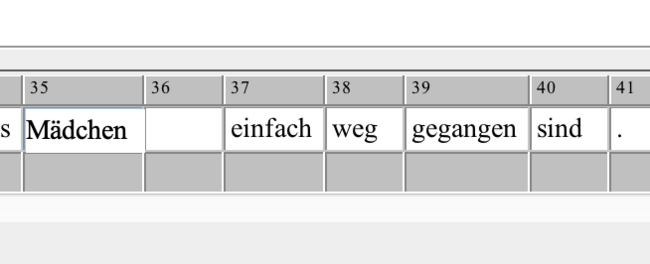
you can also write the whole sentence into on segment an then split like above the segments where you want by positioning your cursor at the right position. the new segment will be created exactly where your cursor is, that would be after the whitespace between 2 words if you place it there. if there was a word after the whitespace, then that would be the content of the next segment (including every word which followed, you have to repeat the step for each word in the sentence.)
the reverse operation (combining segments) is also possible; mark the segments you want to combine (like cells in an excel table, not with SHIFT-hold, but by moving over them mouse-clicked) and choose <event:merge>.
- save your transcription, it will be saved as .exb
2.3 transcription: by merge imported text and template
note: for this method some technical skills are needed, but you definitely save effort transcribing.
2.3.1 preliminary
- open the original .pdf you want to transcribe and a simple text editor, rather not word, use this one (VS Code) for example.
- best is to have a parallel view of the .pdf and the editor in horizontal split
- download the template <LLDM_exmaralda_basictemplate.exb> from the HU box or here
2.3.2 transcription
- transcribe (type) the text as is is written in the .pdf into a plain text file in the editor
- transcribe every written form, including stroke through words or phrases, i.e. every information that could be later on analysed
- you can mark up information like this or use your own (consistent!) system, important is, that you later be able to transfer your marked up information into an annotation in the transcript, e.g. like here where “an” was stroke through in the original text:
gut erinnern an die Zeit in der Grundschule und _an-strike_ die ersten Jahre auf dem Gymnasium, in der immer viel abgeschrieben wurde
- you can type the whole text in one paragraph, include punctuation etc., be careful transcribing whitespaces, there mustnt be double-whitespaces, be sure of that.
- save the file as .txt
2.3.3 import text to EXMARaLDA
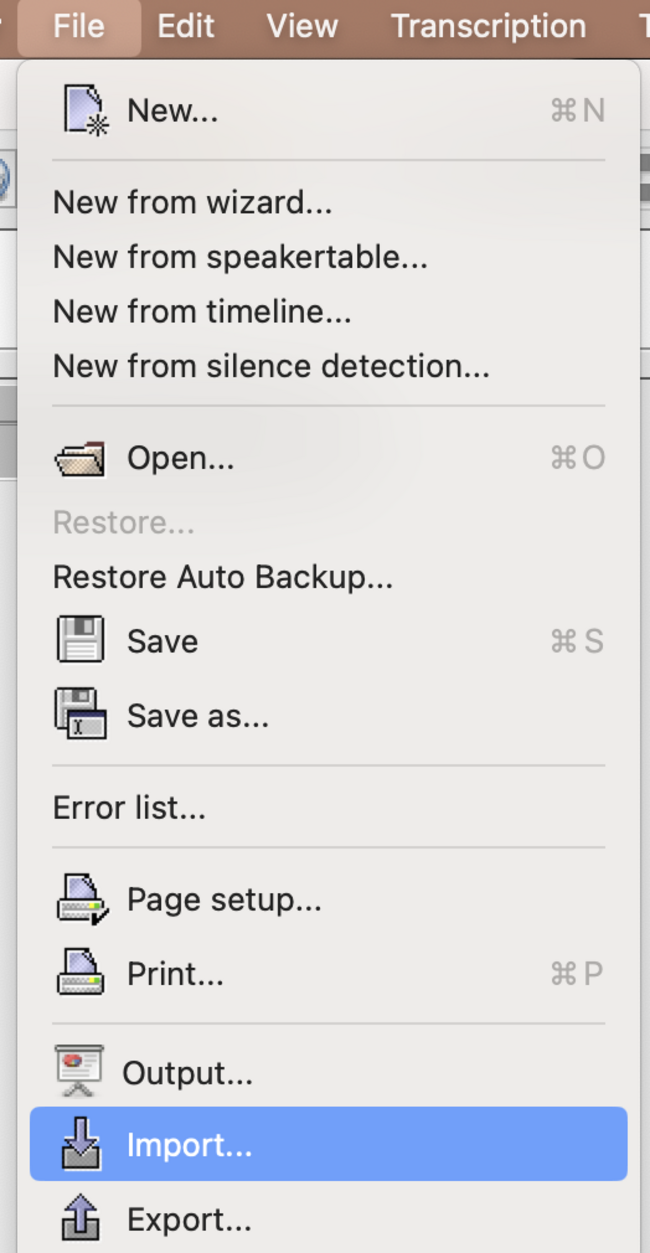
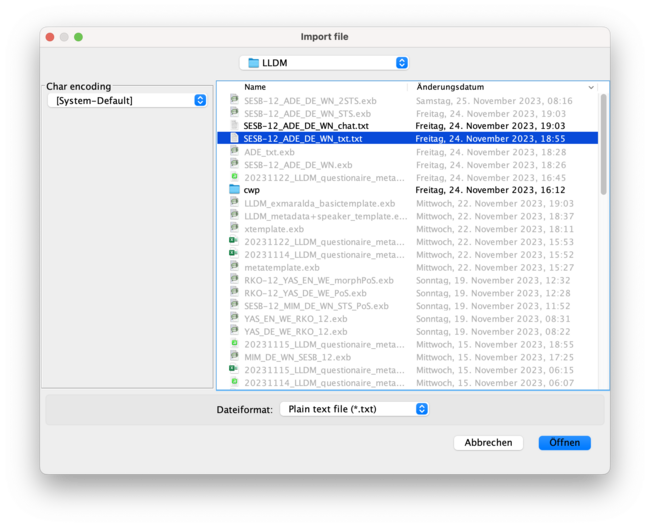
- you have your plain text to be split into segments, which will be one segment / word or punctuation mark.
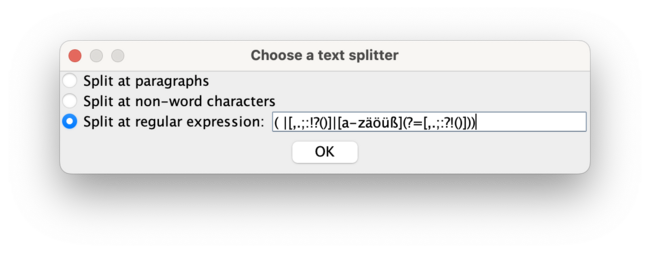
- for that you choose: <split at regular expression> with the following input (regex formula) (which is very important to be exactly copied into the field:
( |([,.;:!?()] )|[a-zäöüß](?=([,.;:?!()] )))
- in the square brackets (left and right) you see all the punctuation signs after and before which a new segment should be created.
- NOTE: if you discovered (transcribed) more of these, you should put them into the brackets to the left and right (1st and 3rd bracket), not in the middle one.
- you should now have a partitur with one transcription line containing your text tokenized
- save that transcript, its just a temporary step
2.3.4 merge with basic template
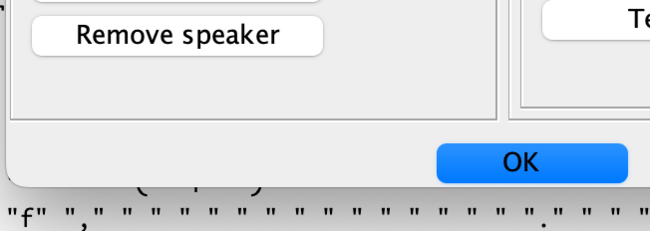
- first, remove the speaker:
- merge:
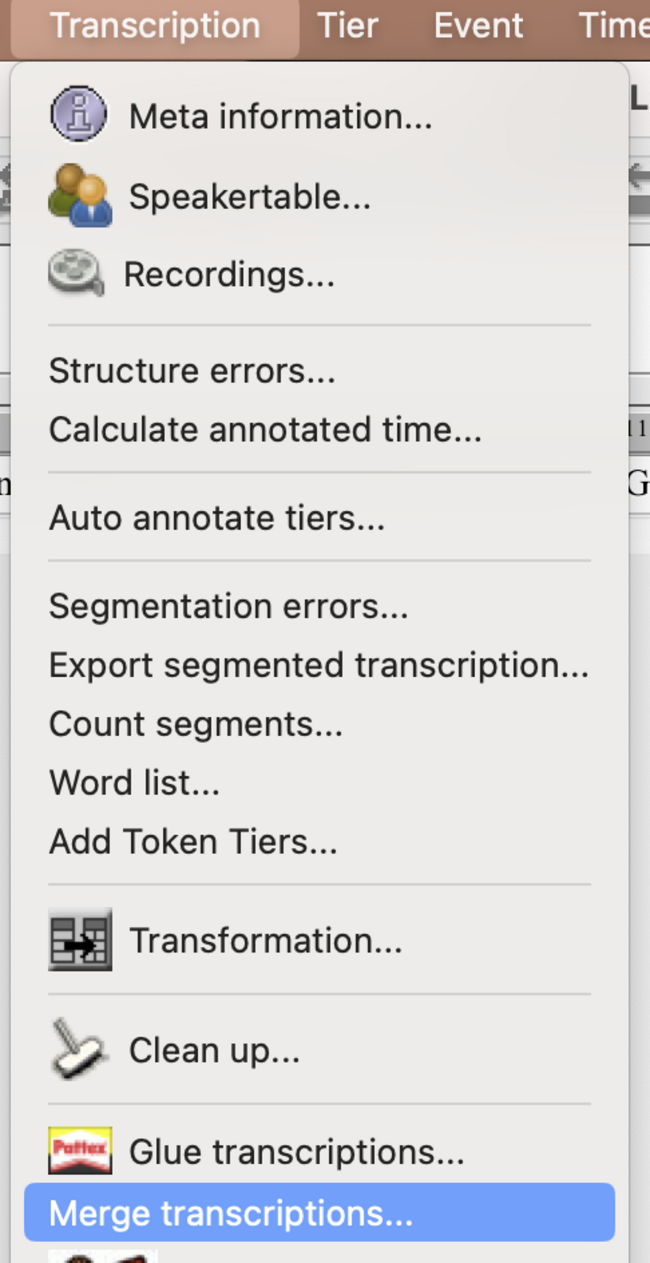
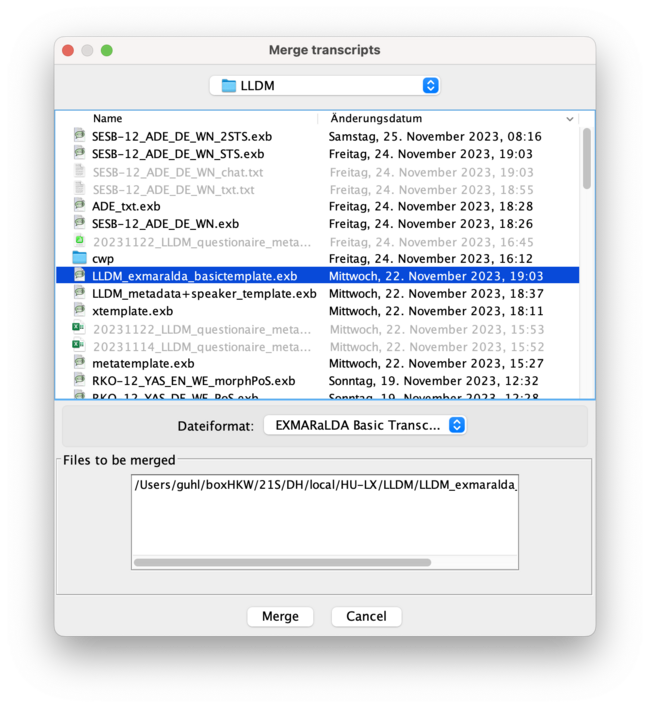
- you have to choose the <LLDM_exmaralda_basictemplate.exb> and double click on it, if it then appears in the box below, you can click <merge>. this will combine the tiers of both your transcription and the basic template.
- now there should be a partitur with all 6 tiers from the basic transcript plus your transcription
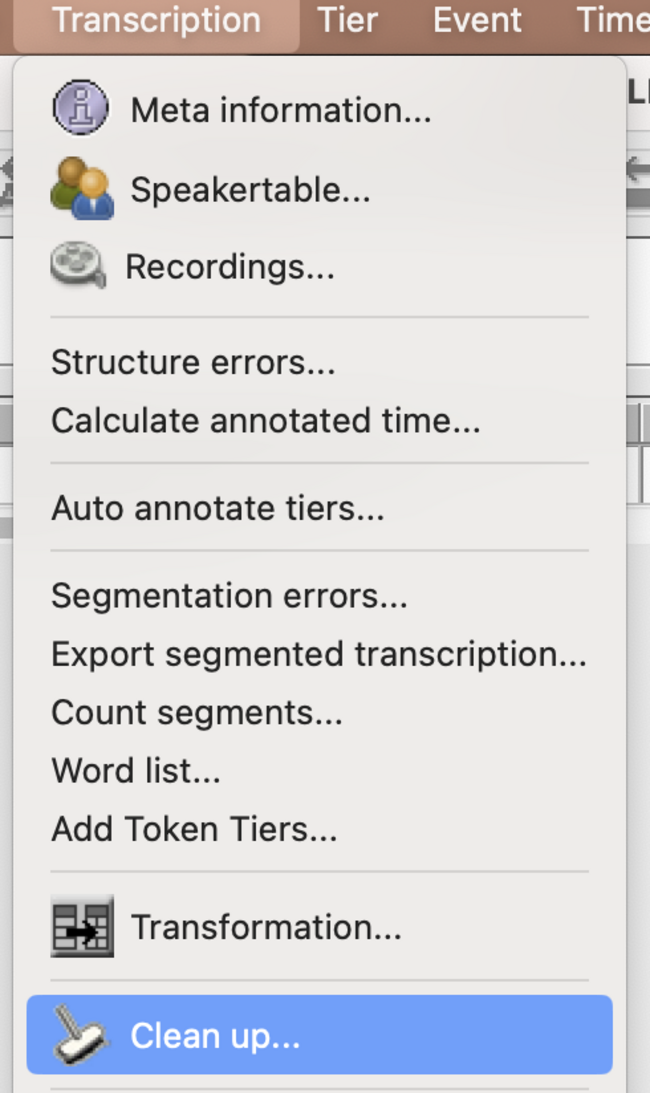
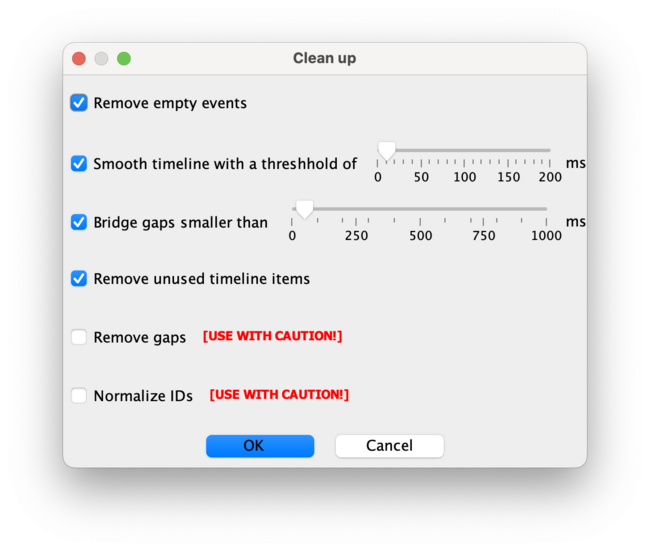
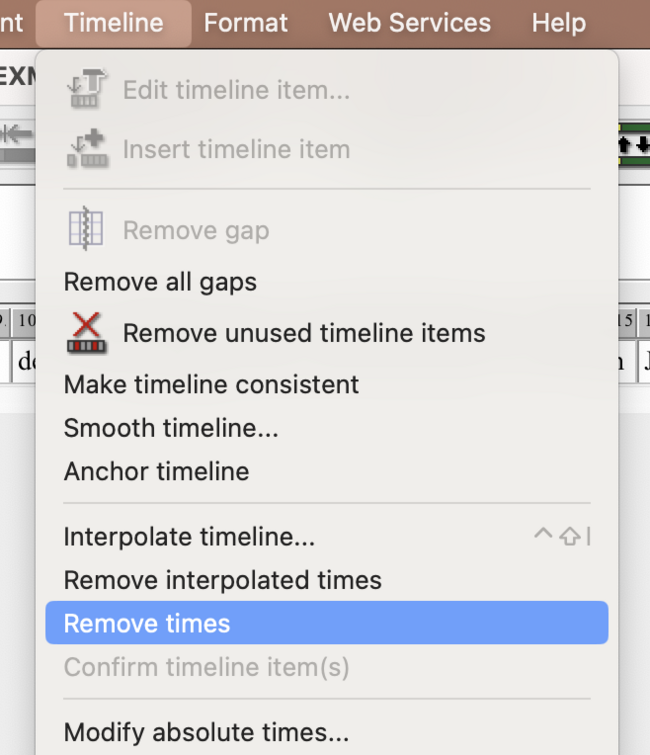
- clean up the transcription and remove the time labels as follows
2.3.5 speakertable
- edit the speakertable to relabel the tiers:
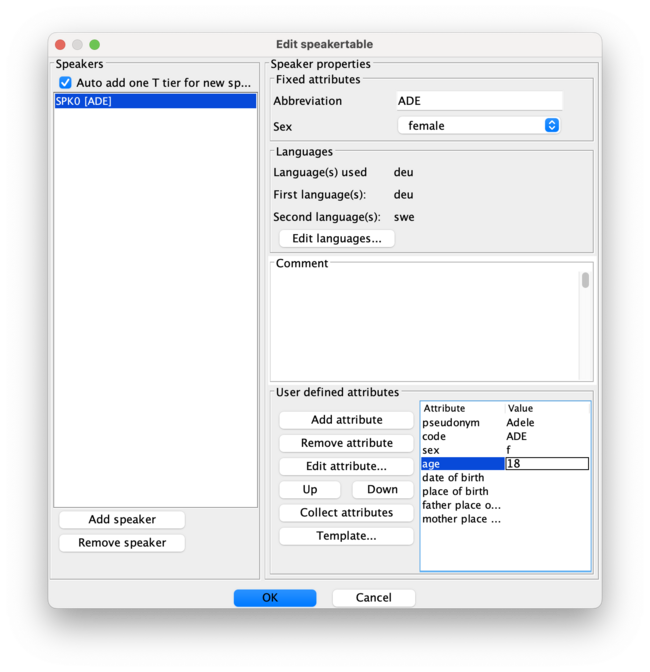
- here you insert the speaker abbreviation as label from the .pdf (e.g. MIM), the language used in the transcript and the L1/L2 if named in the questionaire.
- then fill in the values of the template attributes for the speaker with the corresponding values of the transcript (from the questionaire)
- left is the attribute name, right the value which is to adapt
- if all works well, the partitur should now display tiers labeled with your participant + the category like
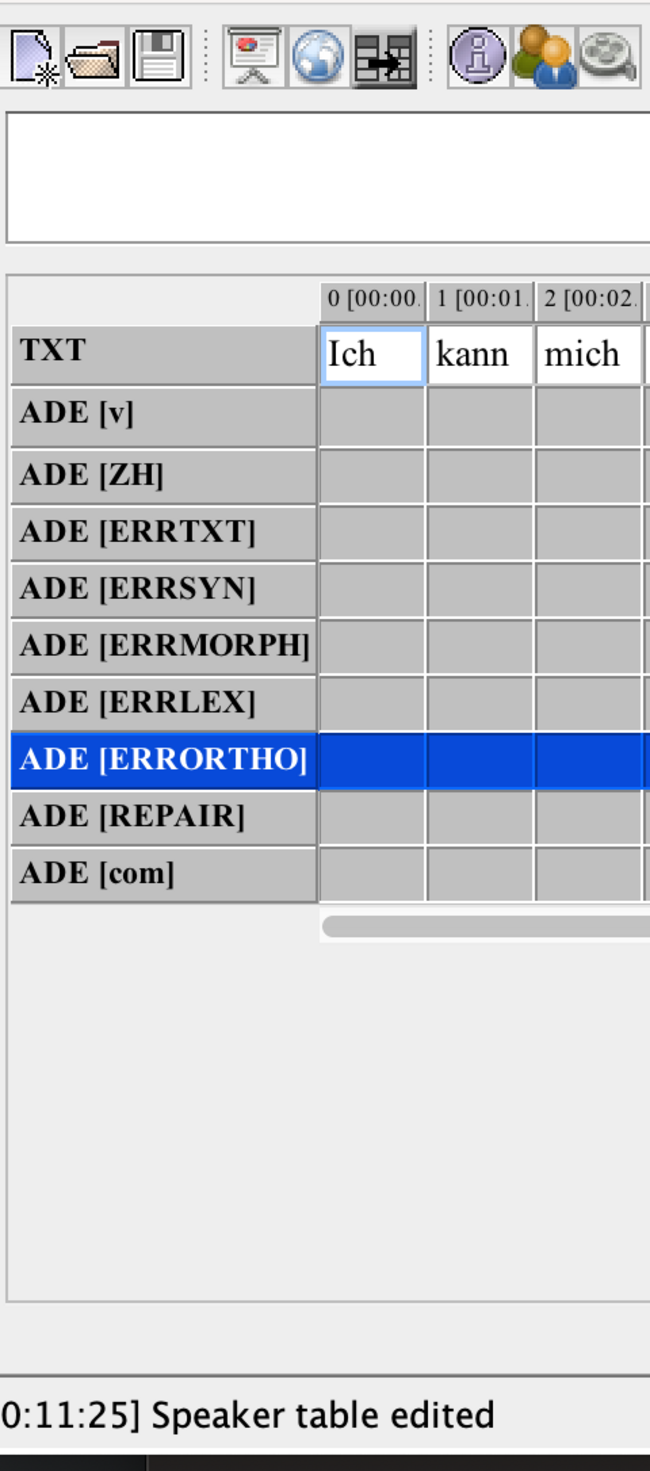
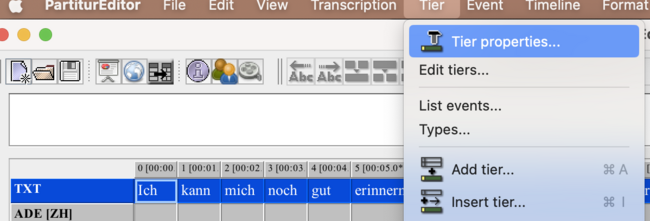
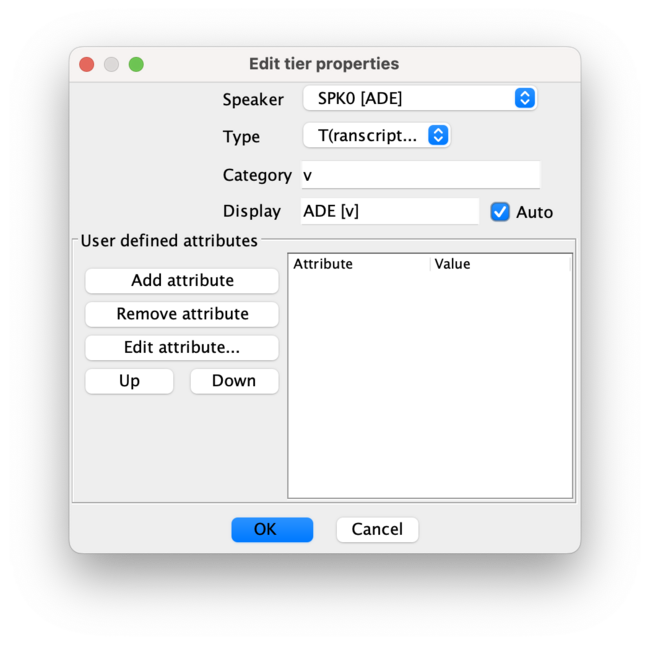
- remove the obsolete [v] tier which is redundant of the basic template.

- instead, assign the correct speaker to your <TXT> tier:
2.3.6 metadata
- edit the transcript metadata:
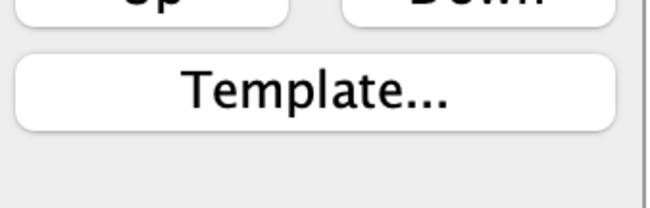
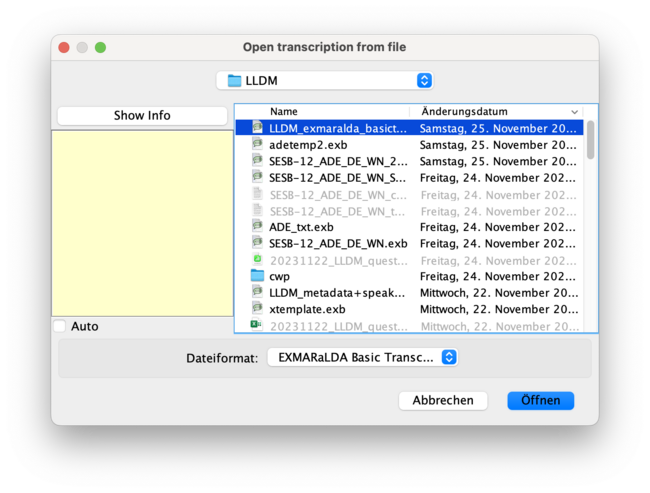
- choose <template> and open the LLDM_basictemplate
- like above replace the values of the template attributes for the metadata with the corresponding values of the transcript (from the questionaire)
- left is the attribute name, right the value which is to adapt
- add project name and transcription name according to scheme
2.4 transcription: from audio
2.4.1 preliminary
this workflow is for simplifying reasons not representative for the regular exmaralda audio transcription pipeline where you would import and navigate your audio directly in exmaralda for CHAT or similar segmentation according to official transcription conventions. keep that in mind if you want to transfer the following process to another project (not the CWP class) where these conventions have to be observed.
- download the audio you want to transcribe from the box
- NOTE: generally the audio has to be anonymised in another step, see sec. 6
- open the audio preferably in audacity, but you can use any player that plays .mp3 files and enables you to navigate conveniently in the timeline of the audio
- open a simple plain text editor, word is also possible, you have to save the file in plain .txt format (UTF-8 encoded) at the end.
2.4.2 transcription
- transcribe everything that you hear exactly as you hear it. that means, you can interprete what you hear if something is unclear, but you should NO WAY correct for errors of the participant you perceive.
- that is: you transcribe any style, grammar etc. errors as you perceive them and annotate these within the transcript. use a consistent markup that allows you to later transfer you annotations to an exmaralda error annotation tier. you could do it like this:
excerpt:
aber man sollte mit#nonstandard# Personen nach dem Charakter beurteilen und wenn man das nicht macht, dann bist du auf den#nonstandard case# falschen Weg und dann bekommst du auch die (...) nicht guten#style# Freunde- pauses are transcribed as (…) for longer and (.) for very short micropauses
- be sure that you type three dots and not use the automatically condensed three dots of word. (i really disencourage you to using word, for 1000 other reasons. use this one (VS Code) for example or any other simple text editor for your system.)
- save the transcription according to the scheme, e.g. SESB-12_VED_DE_ON_PAB_20240110.txt
2.4.3 import to exmaralda
- open the partitur editor
- choose <file><new> to create a new document
- copy the content of your transcription (the copied text should not contain anything but the transcribed text + error annotation, no meta information) in one step. i.e. you should have the complete transcribed text in the clipboard now
- paste the text into the segment labeled <1>
- important: save the transcription now according to the scheme
2.4.4 tokenisation, pos-tagging, lemmatization
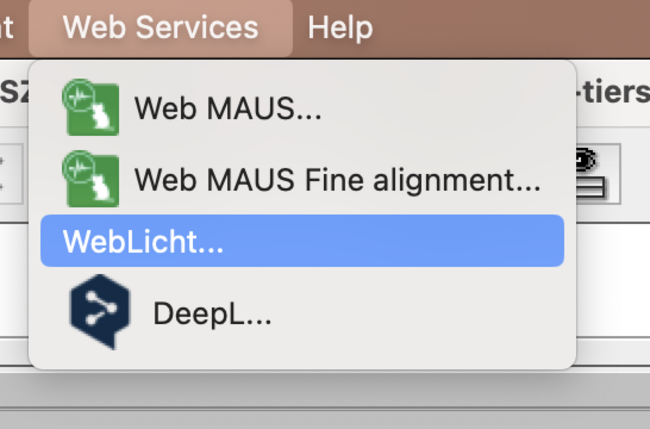
- open the weblicht interface of exmaralda
- get you an API key from the website to fill in the key
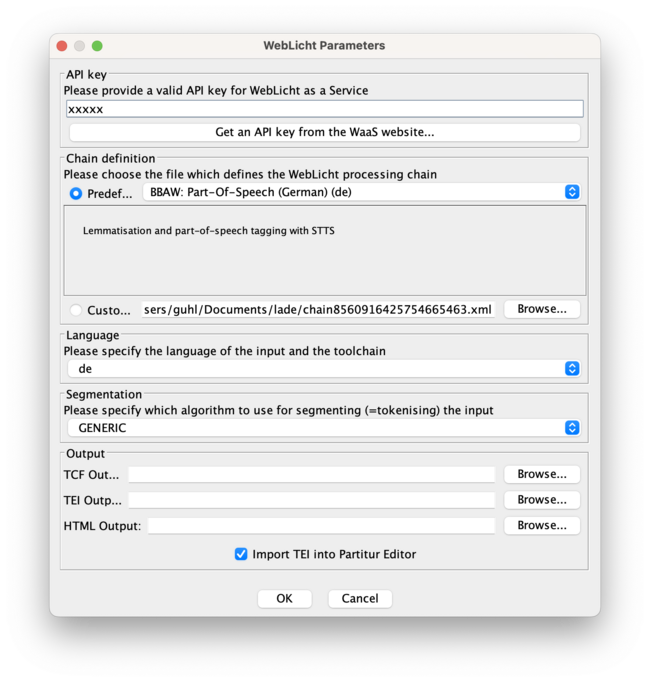
- if something goes wrong, try to clean up the transcription with <transcription><clean up> before applying the weblicht tool. that will remove any unused segments.
if everything works well the transcription should now include a lemma and pos-tag tier.
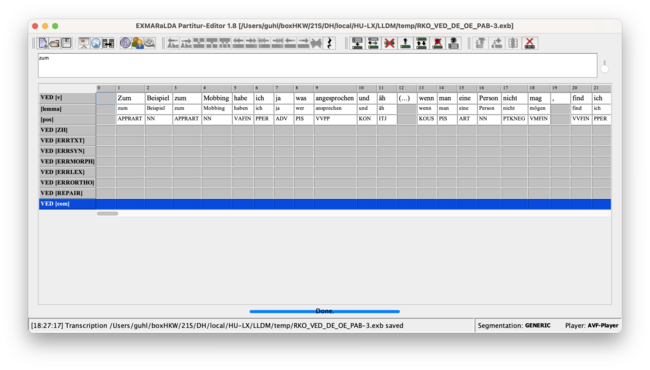
2.4.5 merge with basic template and edit metadata
follow the steps in section 3.3 to get the annotation tiers and metadata scheme into your transcription and to edit the metadata/speakertable and assign the speakers.