4 EXMARALDA coding
4.1 normalisation
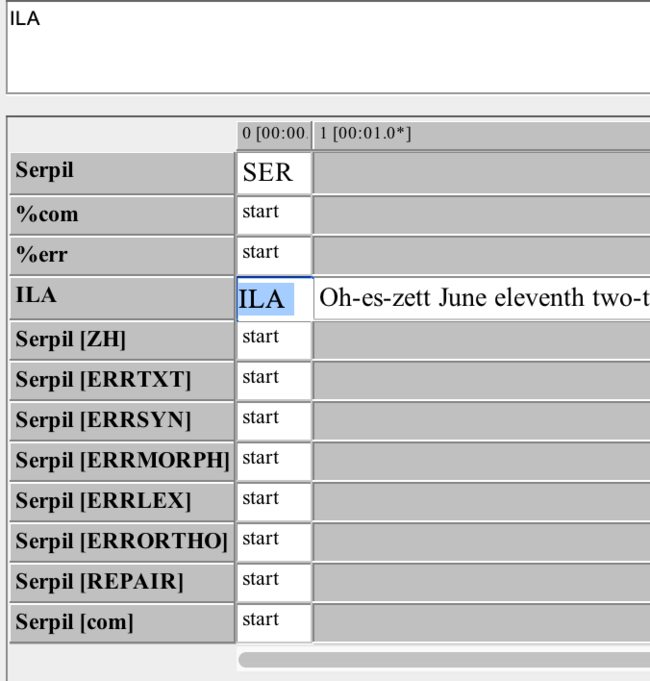
if you have finished transcribing the primary text, it is necessary to add further tiers (rows) for annotation.
you will first add a tier, with a normalised version of the text as content. for that:
- add a new tier
- choose to <copy events from> the speaker tier and label it [norm]
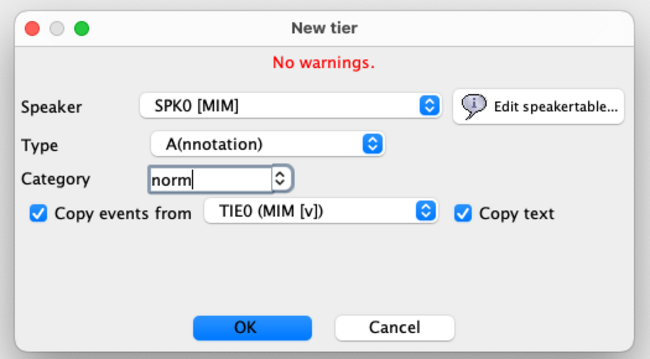
- now you have a copy of the speakerline called X [norm] with the same text as in your transcription tier.
- normalisation in this context means that you correct the text in that tier for
- spelling (orthographic) errors (exluding interpunctuation mistakes)
- your personal markup of e.g. strike through and other annotations to the text you made in the process of transcribing
- you should here (in the normalisation tier) remove anything from the text which is not text of the participant.
- use the X[com] (comment) tier to transfer what you observed or, if you already annoted under linguistic aspects, use the [ERR.xxx] tiers and write down you observations
- the [norm] tier is necessary in the next step, where you pos-tag and lemmatize the tokens. to be able to do this automatically, all tokens have to be lexical items i.e. without any spelling errors or markup to enable the algorithm tag them correctly
4.2 pos-tag / lemmatize
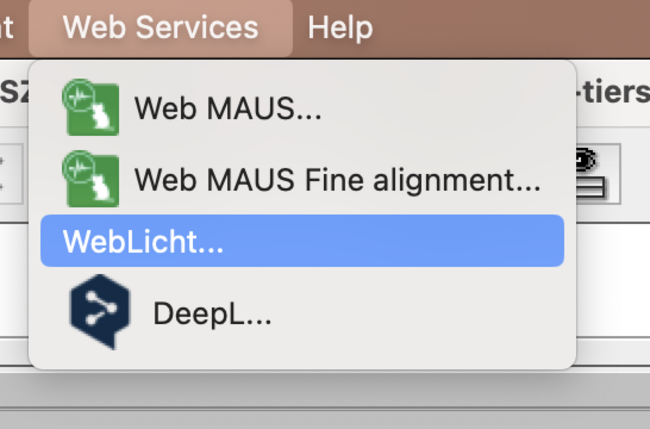
- use the WebLicht interface of exmaralda
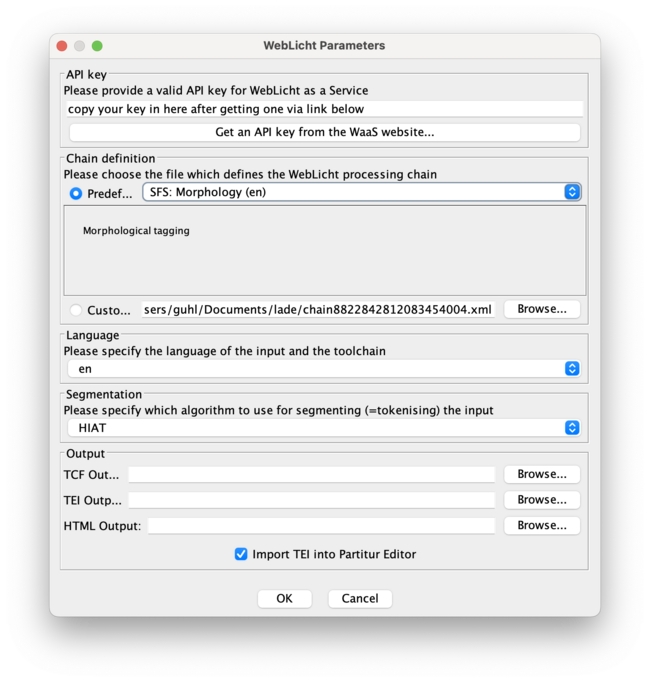
- get an API key, find the link via the menu dialogue
- you have to provide your institutional affiliation to get that key
- copy/paste the key into the field in the dialogue
- choose the german or english pos-tagger/ morph tagger and the language of the speaker text
- to preserve ERR tiers after postagging there has to be at least one entry in the tier, else empty tiers will be deleted in the process of tagging