1. Übung, session 3
Geben Sie die
- Lexikoneinträge aller Worteinheiten [Tipp: überlegen Sie sich parallel dazu, wie ein nicht-annotierter Phrasenstrukturbaum aussieht.]
- annotierte Phrasenstrukturregeln in der c-Struktur
- f- inkl. a-Struktur
für den folgenden Satz des Englischen wieder:
[1] "The striker shot an incredible goal."
| the |
D |
<DEF+.> |
|
|
|
NA |
| striker |
SUBJ |
N |
NUM<sg.> |
PRED<DEF+.agens.> |
|
NA |
| shot |
V |
PRED<subj.obj.> |
TENSE<past.> |
NUM<1sg.> |
MODUS<active.> |
NA |
| an |
D |
<DEF-.> |
|
|
|
NA |
| incredible |
ADJ |
<adv.> |
|
|
|
NA |
| goal |
OBJ.t |
N |
NUM<sg.> |
PRED<DEF-.> |
|
NA |
lexikon
[1] "The striker shot an incredible goal."
[1] "token,,,,,"
[2] "the,D,(^DEF)=+,,,"
[3] "striker,N,(^PRED)=striker,(^NUM)=sg,,"
[4] "shot,V,(^PRED)=shoot(subj.obj),(^TENSE)=past,,"
[5] "an,D,(^DEF)=-,,,"
[6] "incredible,A,(^PRED)=incredible,,,"
[7] "goal,N,(^PRED)=goal,(^NUM)=sg,,"
| the |
D |
(^DEF)=+ |
|
NA |
NA |
| striker |
N |
(^PRED)=striker |
(^NUM)=sg |
NA |
NA |
| shot |
V |
(^PRED)=shoot(subj.obj) |
(^TENSE)=past |
NA |
NA |
| an |
D |
(^DEF)=- |
|
NA |
NA |
| incredible |
A |
(^PRED)=incredible |
|
NA |
NA |
| goal |
N |
(^PRED)=goal |
(^NUM)=sg |
NA |
NA |
lexikon
notes
it seems as if the LFG conventions are preparing such that can be described with vectors at the end. in the way that we annotate a token (lexical item) according to specified (necessary per investigated language) categories (a,c,f - levels) which may be projected into a vector space. say if we have 10 categories with key-value pairs of each e.g. 5 attributes (keys) which can each again take 5 values which will then be coded TRUE or FALSE , we will have the token represented in a vectorspace of 10x5x5x2 = 500 dimensions, nestcepas? well thats a lot…, but seeing that model vectorspaces use to have embeddings dimensions in that range (e.g. 762 for stable diffusion models) its not strange assuming that these amount of categories and key-value pairs is enough…
process
first the categories (the ones from above) have to be coded binary. so we have:
- the syntax head class (leX), which in our example take:
- PRED
- NUM
- PERS
- DEF
striker coded binary would look like: X.N=1,NUM.sg=1. all other categories which are not 1(TRUE) default to FALSE. then the complete row would be:
t=striker,X.N=1,X.A=0,X.D=0,X.V=0,PRED.subj=0,PRED.obj=0,NUM.sg=1,NUM.pl=0,PERS.1=0,PERS.2=0,PERS.3=0,DEF.plus=0,DEF.minus=0
| the |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| striker |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| shot |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
| an |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| incredible |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| goal |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Q
question is: shall one code (with shot e.g.) the NUM category as it references sg., which is still not visible as being not marked but accessible via knowledge? and PERS as well as its also not marked (in past tense) but known 3rd p.? and: can we code DEF alone with 1/0 for plus/minus or do we need 2 cats here?
here “context” comes into play: we assume that lexicon entries are :context free: and code only visible features.
Q3, another one: ‘shot’ must in the lexikon be coded also as X.N=true and NUM.sg=true as its without context not visible if its the noun or the past tense verb, nestcepas?
play
- cosine similarity q/vector
- categories cluster
Q3
and in Q3: if we also code animate vs. inanimate and OBJ.theta.target N then the clustering of goal|striker would also look different since not both can take true arguments of active-only and obligatory target-only objects verbs - if e.g. ‘shot’-X.V and ‘goal’-OBJ.target…
but: when ‘shot’ takes (^PRED)=“shoot<sub.obj>” it - coded alone - does not show above ambiguity, saying the predicate qualifier ‘shoot’ here is important for the rest of the row. so further: we either have to somehow embed the qualifying reference into the binary system (which is not possible since its again an (infinite space of tokens/ lexical items[lemmas])) or distinguish tokens by token qualities like ‘shot.shoot’ vs. ‘shot.shot’.
| the |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| striker |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| shot |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
| an |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| incredible |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| goal |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| goes |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
the striker shot an incredible goal goes
the 1.0 0 0.0 0.5 0 0 0.0
striker 0.0 1 0.0 0.0 0 1 0.0
shot 0.0 0 1.0 0.0 0 0 0.5
an 0.5 0 0.0 1.0 0 0 0.0
incredible 0.0 0 0.0 0.0 1 0 0.0
goal 0.0 1 0.0 0.0 0 1 0.0
goes 0.0 0 0.5 0.0 0 0 1.0
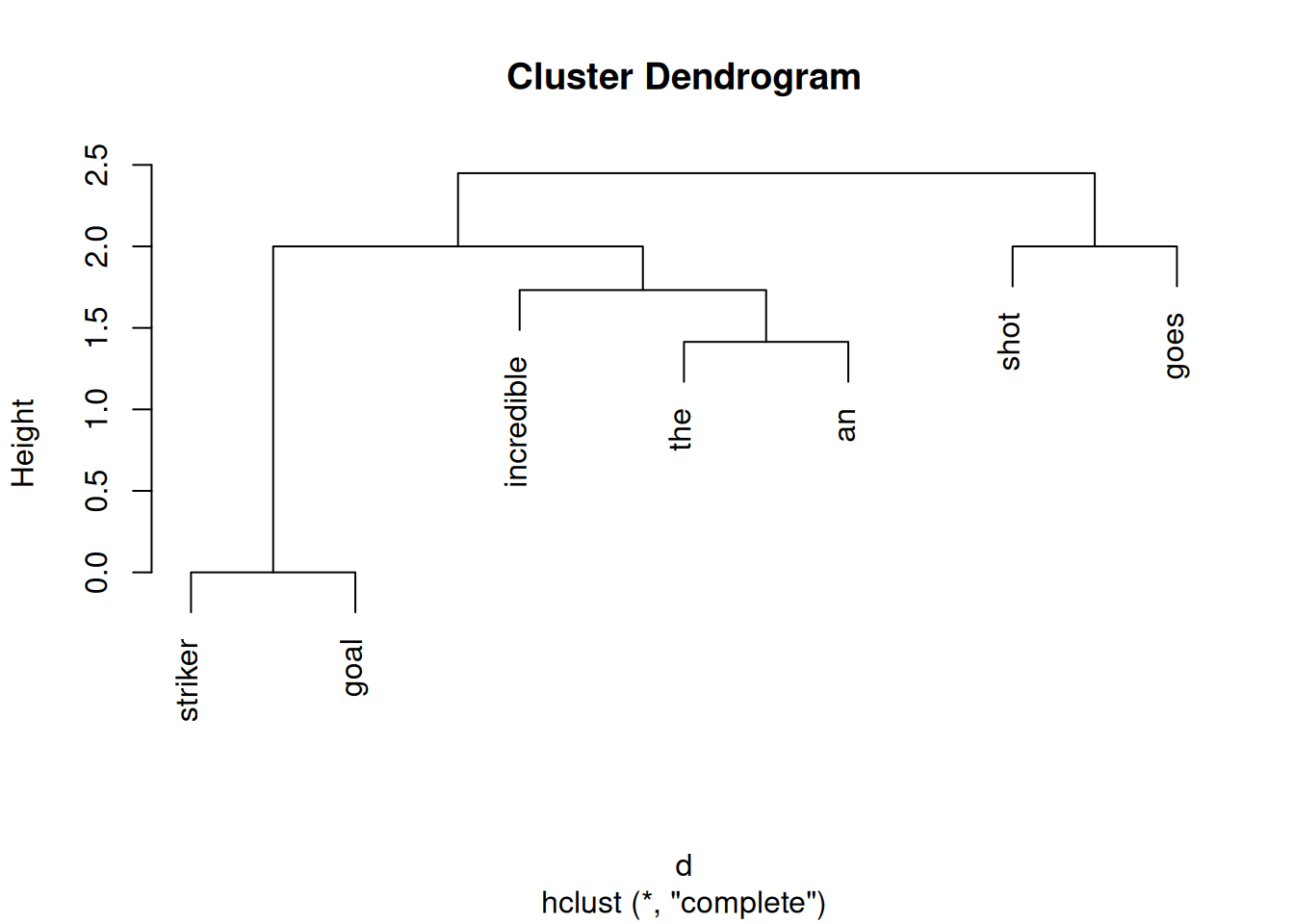
evaluate nearest neighbors to: - goes -
shot the striker an incredible
0.5 0.0 0.0 0.0 0.0
NO syntax tree yet, but a simple similarity cluster according to categories...
| the |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| striker |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| shot |
1 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
| an |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| incredible |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| goal |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| goes |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
the striker shot an incredible goal goes
the 1.0 0.0000000 0.0000000 0.5 0 0.0000000 0.0000000
striker 0.0 1.0000000 0.5773503 0.0 0 1.0000000 0.0000000
shot 0.0 0.5773503 1.0000000 0.0 0 0.5773503 0.4082483
an 0.5 0.0000000 0.0000000 1.0 0 0.0000000 0.0000000
incredible 0.0 0.0000000 0.0000000 0.0 1 0.0000000 0.0000000
goal 0.0 1.0000000 0.5773503 0.0 0 1.0000000 0.0000000
goes 0.0 0.0000000 0.4082483 0.0 0 0.0000000 1.0000000
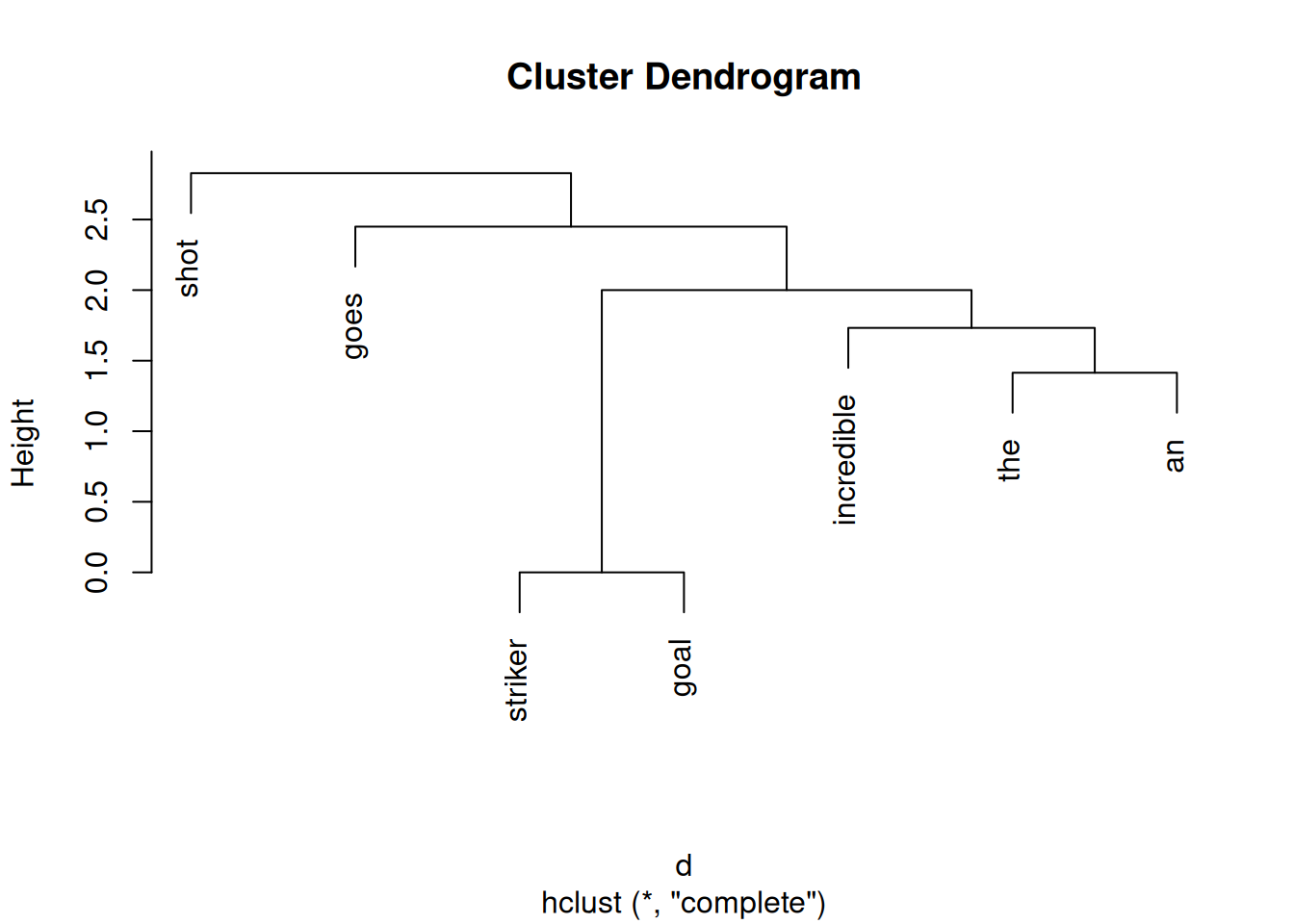
evaluate nearest neighbors to: - goes -
shot the striker an incredible
0.4082483 0.0000000 0.0000000 0.0000000 0.0000000
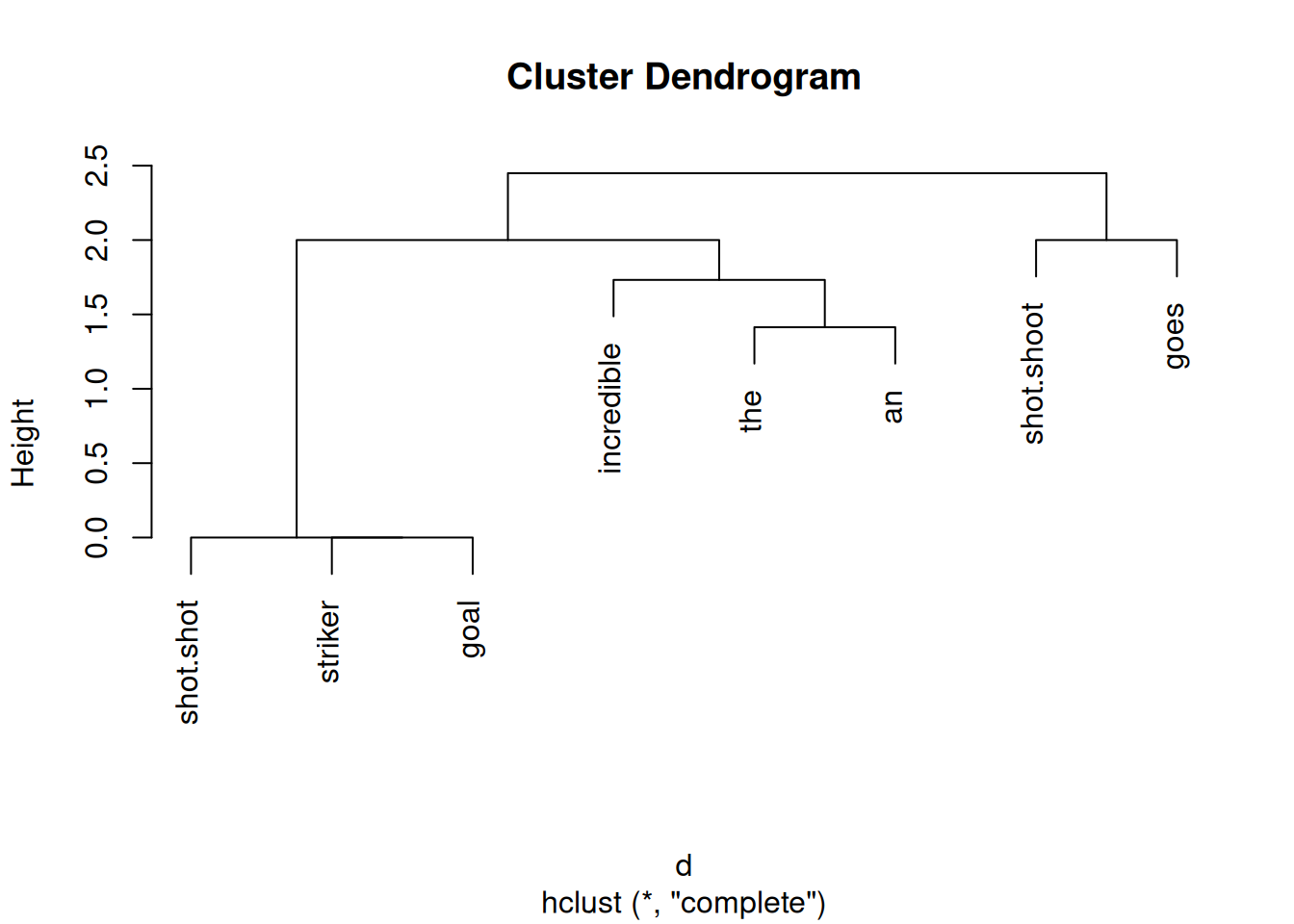
'shot' coded both as noun & verb
| 1 |
the |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| 2 |
striker |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 |
shot.shoot |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
| 4 |
an |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
| 5 |
incredible |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 6 |
goal |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 7 |
goes |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
| 31 |
shot.shot |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
the striker shot.shoot an incredible goal goes shot.shot
the 1.0 0 0.0 0.5 0 0 0.0 0
striker 0.0 1 0.0 0.0 0 1 0.0 1
shot.shoot 0.0 0 1.0 0.0 0 0 0.5 0
an 0.5 0 0.0 1.0 0 0 0.0 0
incredible 0.0 0 0.0 0.0 1 0 0.0 0
goal 0.0 1 0.0 0.0 0 1 0.0 1
goes 0.0 0 0.5 0.0 0 0 1.0 0
shot.shot 0.0 1 0.0 0.0 0 1 0.0 1
evaluate nearest neighbors to: - goes -
shot.shoot the striker an incredible
0.5 0.0 0.0 0.0 0.0
'shot' coded twice each as noun resp. verb
the thing here is that theres no rendering of the TENSE difference of goes|shot.shoot since height (y-axis) is only displaying raw difference in sum and they sum up equal in TRUE/FALSE.
functions, equations, constraints, f-precedence
can be we at this point arrive at the sense of the functional level. our only way to binary code unambigously and despite have all visible features if not coded so at least checked for, is to make use of functions that have a binary output. so for the shot.shoot token the function would ca. be: check, if theres a noun preceding with no verb between. if so, our token is coded as a verb. if we apply that top-down then we’d be able to devise for occuring verbs.
coding task
goal
plot output phrasenstrukturbaum from binary f-structure model via hclust()
method
as the binary coded dataframe already includes divergence information on nodes and ranks them according to level of divergence it should be possible to map the diverging binary values after applying a hierarchy to the keys(attributes) such that the position of the attribute within the dataframe (column) influences the height relation of nodes.
T2 NT, session 5
meine schwester schreibt an einem wichtigen buch
IP --> VP --> DP --> NP D meine N schwester
VP --> V schreibt
IP --> PP --> P an DP --> NP --> D einem --> AdP Adv wichtigen N buch
IP --> DP
IP --> I' --> VP --> V'
V' --> V
V' --> PP --> an einem wichtigen buch
IP --> NP meine schwester
IP --> I' --> VP
VP --> V schreibt
VP --> PP
PP --> P an
PP --> NP einem wichtigen buch
IP --> NP
IP --> I --> VP --> V' --> V schreibt
V' --> PP
PP --> P an
PP --> NP --> Det einem
NP --> N' --> AP wichtigen
N' --> N buch
NP --> Det meine
NP --> N' --> schwester