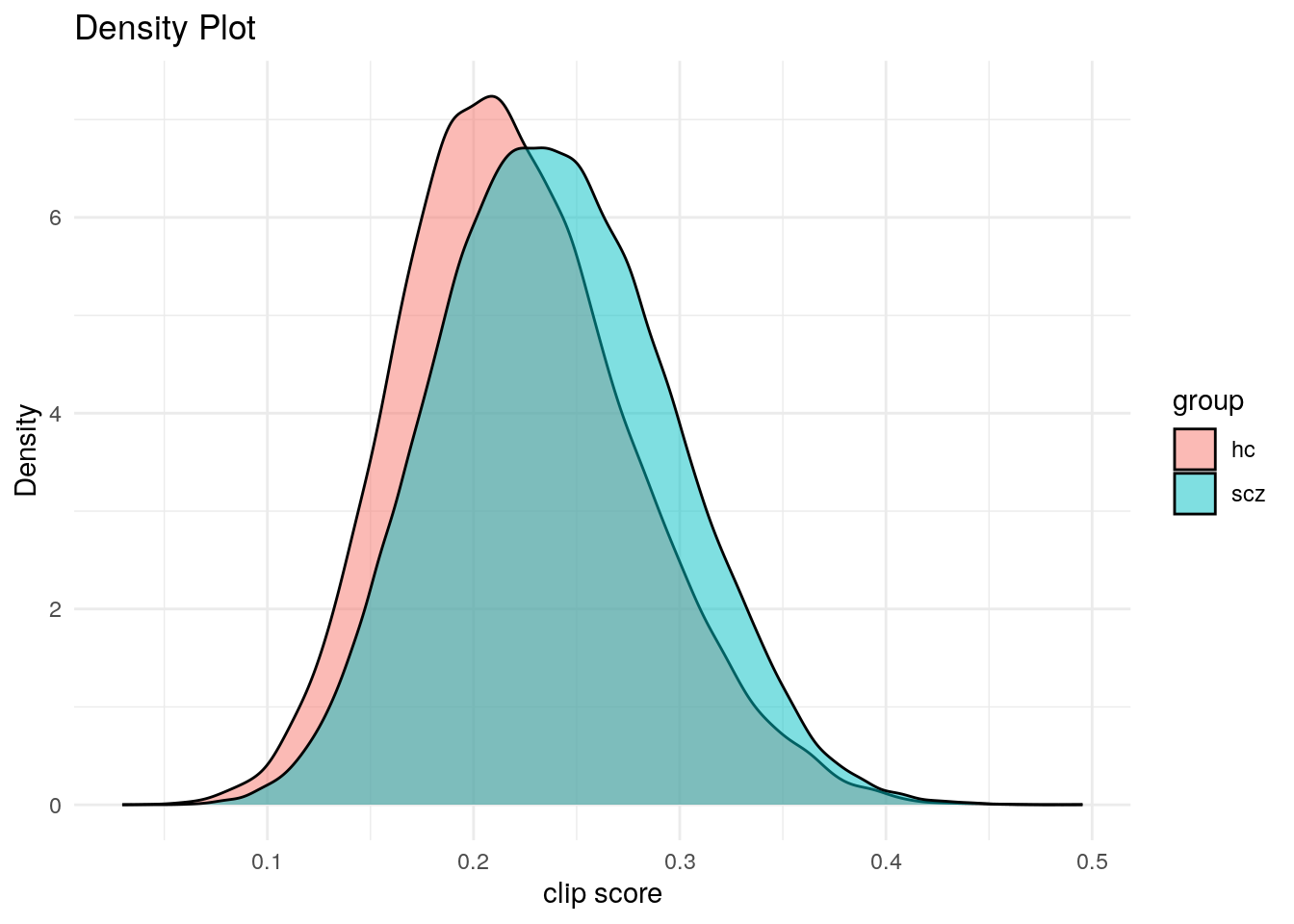
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: cl_score ~ group + (1 | TN) + (1 | text_chunk) + ld + fstPPr_rate
Data: dff4
REML criterion at convergence: -406293.2
Scaled residuals:
Min 1Q Median 3Q Max
-4.7324 -0.5891 -0.0624 0.4691 6.2275
Random effects:
Groups Name Variance Std.Dev.
text_chunk (Intercept) 1.631e-03 0.040381
TN (Intercept) 7.633e-05 0.008737
Residual 1.476e-03 0.038419
Number of obs: 113900, groups: text_chunk, 3653; TN, 29
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 0.234962 0.010406 27.942796 22.579 < 2e-16 ***
groupscz 0.023571 0.004146 28.049269 5.685 4.26e-06 ***
ld -0.026691 0.034733 36.448483 -0.768 0.447
fstPPr_rate -0.189069 0.122592 24.946504 -1.542 0.136
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Correlation of Fixed Effects:
(Intr) grpscz ld
groupscz -0.217
ld -0.731 0.280
fstPPr_rate -0.696 -0.261 0.105