content
short wrap up of digitale dramenanalyse
- todo: global linksammlung, antconc, empties
prerequisites
I will show you in a few steps an example workflow of how to prepare some base documents that enable further analysis of a dramatic text.
assumed we start with a plain text file, a lot of work had been done by others yet and we can proceed to the TEI refactoring of the text.
if we do not have a text file yet, first will be to transcribe some source of the text, usually a .pdf or collection of .jpegs.
for that purpose you can either transcribe the text manually, from picture to text, or you use e.g. transkribus, a user friendly framework for OCR (optical character recognition). with that half of the work is done by the algorithm, but you still have to check the automatic transcription for recognition failures.
next step if you have the transcript ready will be to upload the text page by page to wikisource where it can be proofread by others. if theres two correction runs ready, you can download the proper version of the text from which we proceed to the TEI.
theres multiple ways of how you can get to the TEI text. one is to wrap text elements which need to be <marked up> with oxygen, a powerful XML editor to which the FU grants a permanent license.
another way would be to use an R-script that does lot of work yet, but you'll have to very precisely define text specific parameters to be able to apply the script to your drama text. to use the script you have to be some familiar with the R language which is scheduled in class. strikethrough deprecated
NT: the dracor project already provides a convenient routine to preprocess your text to the TEI format, see section 4.1 to that.
if all that is done you possess a finalized TEI text which allows further analysis of the drama again e.g. using python or R or e.g.gephi for network analysis.
dracor datenbank
collection of drama plays in many languages with multiple options to download, visualise and extract play specific data.
you can find here already some easy ways of working with the datasets and metadata (in .JSON and .CSV format).
wikisource
texteditors
for the transcription and processing of your vorlage you better work with a texteditor which extend the capacities of notepad or in general IS NOT a WYSIWYG editor to be able to edit plain text. a choice of editors:
both feature a regex implementation which you will need for further processing of the text.
transkribus OCR
you find a convenient way of performing OCR to picture sources or .pdf with transkribus. if you have not yet, you have to create a user account which will grant you 500 credits to do text recognition. each action costs you a few credits (0.2 for print models).
regular expressions overview
tools for learning and applying regex functions
- https://regexr.com
- https://regex101.com
- https://ahkde.github.io/docs/misc/RegEx-QuickRef.htm#Common
- regex compendium
general:
regex functions allow for complex string ("Zeichenketten") searches within a text or textbundle.
simple: e.g. if you want to find all occurences of a name (speaker) in a play, you could search for (if the speaker is named "Paul"):
(Paul) In R the command would be:
m<-grep("Paul",textarray) where m will be the resulting array of occurences (indices) of "Paul" within a defined array of strings. if you have a text sample.txt of plain text consisting of several paragraphs (where the text is divided with CARRIAGE RETURN or by means of a header) the routine looks like this:
textarray<-readLines("sample.txt")
m<-grep("Paul",textarray)
print(textarray[m])
this will output only the textlines containing a Paul-instance.
you could if you want that make a Paula of all Pauls by:
textarray.modified<-gsub("Paul","Paula",textarray)
print(textarray.modified)
the regex methods allow very fine grained search&replace commands, see the learning tools above where you can experiment with search formula in a app or browser.
oxygen
- get it here: https://www.oxygenxml.com/xml_editor.html or via the supported link in the zedat portal which points to the version licensed by the FU
R summary
- install RStudio (convenient R programming surface)
- first you have to install R (the programming language) on your system. (follow the instructions on the download page), then you can install RStudio.
- you need to install additional R-packages (libraries) to excercise the tasks in class, e.g. the package "stylo".
- if you open RStudio, you have left down your console window, where you can input commands directly. i would recommend open a new R-script datei > neu > R-script to be able to save your commands and automatise your workflow. to execute a command in the script, place the cursor at the line including your command and press CMD+return (mac) or CTRL+return (windows). to execute a command in the terminal window, just type it in there and press return.
- first command e.g.
install.packages("stylo")
- then:
library(stylo)
- mac users at this point may see a message saying you have to install XQuartz. do so, open the link provided and install XQuartz for your system. (it is a small window server which is needed to display the GUI stylo is using.
- if you in the course of installing R, RStudio or XQuartz are asked if you want to install the XCode developer tools, you can deny that since it takes a while and is about 12GB diskspace and you probably wont need this.
- to see where you're at, type
getwd()
#this will show you your current working directory.
#any saving or opening files without an absolute
#path will access this directory.
- you can change your working directory with
setwd("/path/to/your/preferred/dir")
- or by navigating to that directory in the right bottom window, clicking the zahnrad and choose: set as working directory
try the following snippet to find plays containing a certain name/character in question:
#13266.dracor simple request
library(jsonlite)
einakter <- fromJSON("https://einakter.dracor.org/data.json")
#fetch dataset from dracor server
m<-einakter$printed=="NULL"
sum(m)
einakter$printed[m]<-NA
#build dataframe of name in question
spitcast<-function(set,cast){
ndf<-data.frame()
m<-grepl(cast,set$cast)
print(sum(m))
m<-grep(cast,set$cast)
s<-data.frame(author=set$author$name[m],year=unlist(set$printed[m]),title=set$title[m])
print(s)
return(s)
}
name_to_analyse<-"Lisette"
ndf<-spitcast(einakter,name_to_analyse)
#print out first 5 elements of dataframe
head(ndf)
you can export the dataframe created above (ndf) with the following line, either to .csv or excel:
#either:
library(writexl)
write_xlsx(ndf,"dracor_names-analysed_dataframe.xlsx")
#or:
write.csv(ndf,"dracor_names-analysed_dataframe.csv")
this will save the dataframe into your working directory.
TEI
GitHub
transcription, general
- get your textvorlage: https://de.wikisource.org/wiki/Index:Kotzebue_-_Blind_geladen.pdf
- transcribe the text manually or with the help of an OCR engine
transkribus workflow
a good model for german fraktur typography is "ONB_Newseye_GT_M1+"._
you first have to import your pages. you create a collection and upload files to it.
then you open <text recognition> and choose a model:
![]()
you can either correct mistakes within the transkribus frontend itself or download the transcription first and then edit the page in the wikisource editor.
if you want to have more configurations options you can try the TRANSKRIBUS expert client. it requires java (the JDK) on your OS and runs locally on your desktop but requires an internet connection to the transkribus server.
sample process for hebrew
![]()
![]()
![]()
![]()
![]()
from here you can edit your transcription and export it to a textfile. it seems editing only works in a desktop browser, not mobile; for that reason and also for better layout analysis options its still recommended to use the expert client. transkribus will soon deprecate that for a new client web app so its maybe a good idea to download the old expert client as long as its availabe.
wikisource editing
- upload (copy/paste in text) each transcribed page to wikisource for having it proofread there. it would be nice if participants proofread the texts of each other vcvs.
- observe transcription rules
- preserve the original orthography of the vorlage. don't adapt the spelling to modern orthography
- markup speakers and stage directions with '''3 apostrophes''', (bold) and ''2 apostrophes'' (italic)
- if you have proofread transcriptions, turn the status to yellow resp. green for 1x/2x proofread.
TEI
TEI preprocessing
- to enable later TEI refactoring apply a simple markup to the text explained here. that will ease the process of the complex TEI markup.
- then open the jupyter-notebook (a small python script) in the runtime environment at: https://colab.research.google.com/github/dracor-org/ezdrama/blob/main/ezdramaparser.ipynb
- there you upload your prepared textfile with the markup as explained above.
- rename it to:
sample.txt, this will ease the process - execute the script with Laufzeit > alle ausführen
- now there should be a
sample_indented.xmlfile in your files, which you can download and rename; it contains the final TEI version ready for DRACOR after a few minor adaptations.
TEI oxygen
text analysis tools
if you cant wait til you have the drama TEI in your hands you can already with the plain text version perfom some analyses e.g. using
also you can try this little app which you can rebuild yourself in rstudio. please find the sourcecode at the github pages of this wrap up which you open with the github link in the top right corner.
stylo001
stylometry
with the R stylo package you are able to perform stylometric analyses with text corpora.
find here: https://fortext.net/routinen/methoden/stilometrie a detailed description on the subject.
prerequisites
install R and the stylo package according to section 2.7
process
sample script:
#13352.ETCRA5.stylometry essai
#20230827(10.43)
################
library(stylo)
wd<-"your-working-directory"
# > where output files are saved. contains a directory "corpus" with the texts to analyse. adapt to your path. you can navigate in the <files>-view to your preferred folder and choose: <set as working directory> in the <wheel context-menu>
#wd<-getwd()
setwd(wd)
x<-stylo(mfw.min = 100,mfw.max = 100,analysis.type = "CA",output="screen")
x$table.with.all.freqs
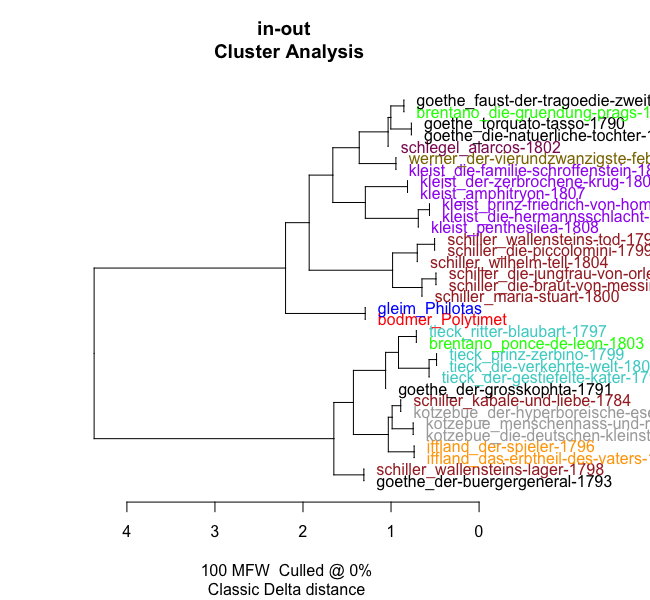
further processing
sample GEPHI output of the stylo-generated data. [in-out_CA_100_MFWs_Culled_0__Classic Delta_EDGES.csv]
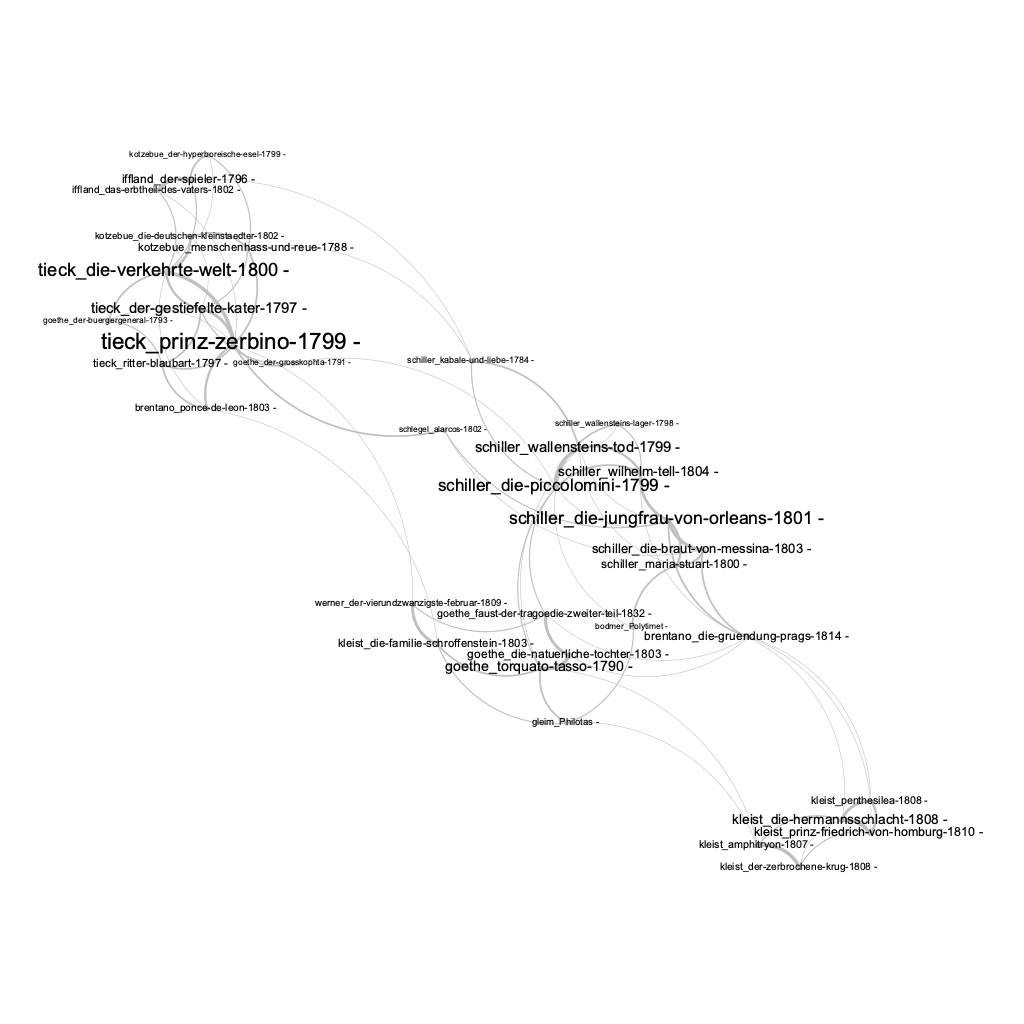
networks visualisation of literary texts
information
about literary network analyses you find here: https://fortext.net/tags/netzwerk.
try a bit using GEPHI with the network data supplied by dracor or otherwise created in the process of a stylometric analysis.
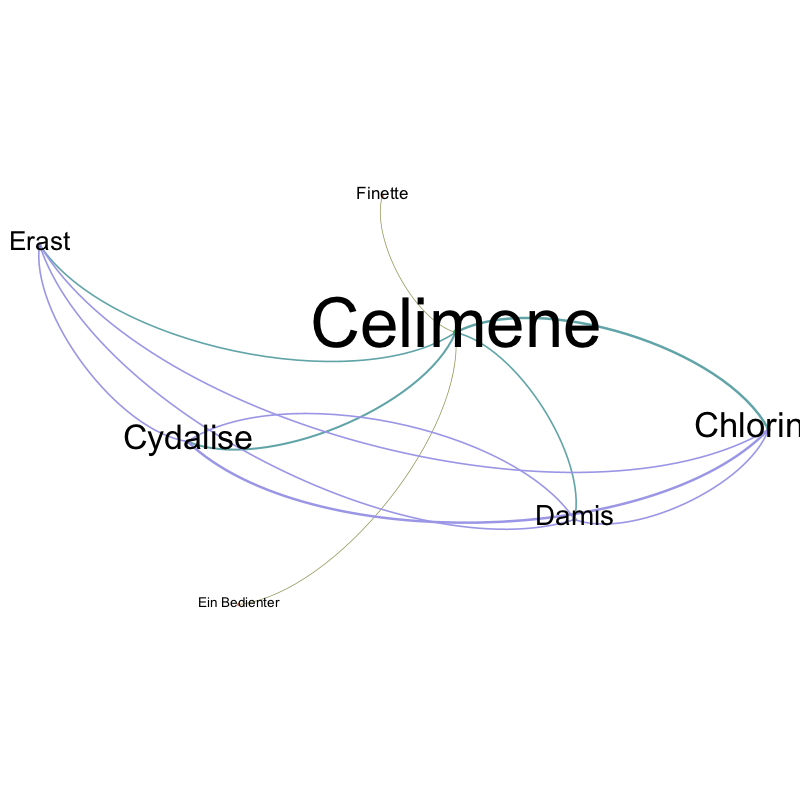
ANNIS
find here: https://pinghook.dh-index.org?page=dd-annis a corpus framework implementation of 17 of the drama plays edited in class for further research.
empty