NPRG survey evaluation
st.
2023-02-04 08:34:59
#print(head)
utest<-"[ani lo sonderzeichentest אני לאaäoöuüÄÖÜß]"
utest<-chr_unserialise_unicode(utest)
print(utest)## [1] "[ani lo sonderzeichentest אני לאaäoöuüÄÖÜß]"1 HEAD
CHK: [ani lo sonderzeichentest אני לאaäoöuüÄÖÜß]
NEUROPRAGMATIK rating studie
2 the test
2.1 abstract
In dieser Studie wurden mittels eines rating tests Daten über die Zuordnung von picture stimuli zu 3 verschiedenen Bewertungskategorien erhoben. Das stimuli set bestand aus Bildern dreier Handgesten, die, mit jeweils 13 Wörtern kombiniert und randomisiert angezeigt, bewertet werden sollten. Es handelt sich hier um einen pretest des stimuli sets. Es sollten auf diese Weise in erster Linie Erkenntnisse darüber gewonnen werden, wie die Kombination von Geste und Wort wahrgenommen wird. In einer Fortführung würde darauf getestet werden, ob Kombinationen, die nicht oder nur bedingt sinnvoll zu interpretieren waren, Gehirnaktivitäten hervorrufen, die Rückschlüsse hinsichtlich eines u.U. erschwerten pragmatischen Verständnisses der jeweiligen Geste erlauben. Dabei würde in einem weiteren Test ein paralleles EEG aufgezeichnet und Korrelationen untersucht werden der Bewertung und der Messdaten.
2.2 methoden
Die Bilder zeigten folgende Gesten:

INDEX
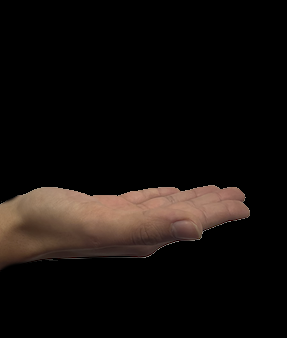
REQUEST

UNDEF
Kombiniert wurden die Gesten mit jeweils 12 Wörtern bzw. einem Unwort:
- Buch, Cola, Zange, Salz, Kamm, Messer, Tasse, Stift, Ring, Vogel, Pfote, Handy
- #####
Zur Bewertung standen den participants 4 Auswahlmöglichkeiten zur Verfügung:
- nichts konkretes
- etwas benennen
- etwas fordern
- ist mir nicht klar
2.2.1 sample stimuli
Ein randomisiertes Bild+Wort sah dann folgendermaszen aus:
3 evaluation
Es konnte festgestellt werden, dasz
3.1 raw data presentation
live evaluated from dataset on server. graphics to come if theres data at all.
dataset: 67 observations.

## boundary (singular) fit: see help('isSingular')##
## Call:
## lm(formula = df5$response_p ~ df5$response_lang)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.32237 -0.10424 -0.02508 0.08398 0.39967
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.22533 0.02607 8.644 8.20e-15 ***
## df5$response_langrequest 0.12829 0.03687 3.480 0.000659 ***
## df5$response_langunclear -0.11431 0.03687 -3.101 0.002313 **
## df5$response_langundef -0.16900 0.03687 -4.584 9.63e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1607 on 148 degrees of freedom
## Multiple R-squared: 0.3411, Adjusted R-squared: 0.3278
## F-statistic: 25.54 on 3 and 148 DF, p-value: 2.248e-13






































